
صدای فراگیر
در این مقاله در صوت پلاس درباره مقدمه ای بر تعریف صدا فراگیر صحبت می کنیم.
صدای همه جانبه یا صدا فراگیر پتانسیل خلاقانه عظیمی برای تولید موسیقی دارد، اما به سختی میتوان ذهن شما را درگیر کرد.
از وینیل طولانی پخش، کارتریج هشت تراک و کاست فشرده گرفته تا CD، Minidisc و MP3، اکثر فرمت های صوتی مصرف کننده یک هدف مشترک دارندکه نام آن استریو است.
آنها حاوی دو سیگنال صوتی مجزا هستند که برای پخش از طریق دو اسپیکر یا گوشی طراحی شده اند. شنونده ای که بین این اسپیکرها قرار می گیرد، یک “صحنه صدا” یا پانوراما را می شنود که در آن منابع فردی در موقعیت های خاص ظاهر می شوند.
به عنوان مثال، یک تک آواز در سطوح مساوی در هر دو کانال به صورت نیمه راه بین دو اسپیکر، مستقیماً در مرکز شنیده می شود.
این توهم چشمگیر است، اما محدودیت هم دارد. این به ما امکان می دهد منابع را در امتداد یک خط بین دو اسپیکر، و به عنوان نزدیک یا دور، بومی سازی کنیم، اما نمی تواند حس ارتفاع را منتقل کند، یا به طور قابل اعتمادی ما را متقاعد کند که صدا از پشت سر ما می آید.
در طول سالها، تلاشهای متعددی برای غلبه بر این محدودیتها صورت گرفته است که مهمترین آنها صدای چهارصدایی در دهه ۷۰، دالبی استریو (ProLogic) در دهههای ۸۰ و ۹۰ میلادی و صدای فراگیر ۵.۱ در اوایل این قرن بود.
با این حال، اینها فقط در سینما به موفقیت پایدار دست یافتند. علی رغم سرمایهگذاری قابل توجه شرکتهای ضبط، مخاطبان داخلی به فرمتهای جدید علاقه نشان ندادند.
چندین دلیل برای این بود. بهعنوان محصولات ممتاز، ضبطهای چهارصدایی، دیسکهای DVD-Audio و SACDهای چند کاناله، گرانتر از نسخههای استریو همان مواد بودند.
از آنها نمی توان به راحتی در هدفون لذت برد، به تجهیزات پخش تخصصی، از جمله حداقل چهار اسپیکر نیاز داشت. که این مسئله پرهزینه بود، و در بسیاری از محیطهای خانه غیرعملی یا حداقل نامطلوب بود.
شکست پیوند

صدای فراگیر چیست؟
وجه اشترک استریو، چهارگانه و 5.1 این است که فرمت های مبتنی بر کانال هستند، به این معنی که یک رابطه ثابت بین تعداد کانال و تعداد اسپیکر وجود دارد.
هر کانال مجزا سیگنالی را حمل میکند که برای اسپیکر خاصی تعیین شده است و خود اسپیکرها باید در یک رابطه فیزیکی خاص پیکربندی شوند.در فضای مناسب، با تنظیم درست همه چیز، تجربه می تواند جادویی باشد. اما در عمل، چنین فضاها و چیدمانهایی کم بود.
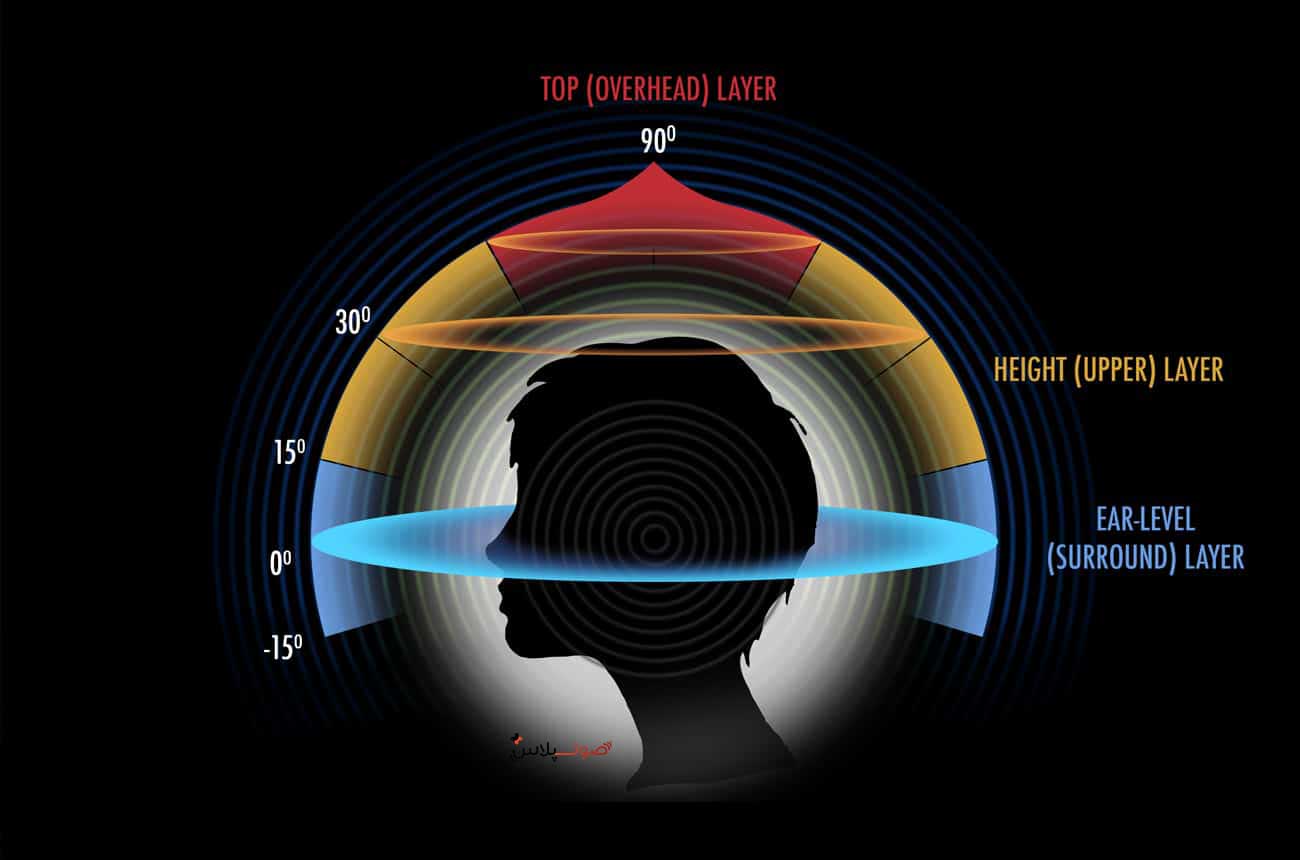
دو ویژگی کلیدی در صدای فراگیر مدرن وجود دارد. یکی این است که آنها فقط اطراف را در صفحه افقی نشان نمی دهند: آنها همچنین حاوی اطلاعات ارتفاع معنی داری هستند که به صداها اجازه می دهد تا بالاتر از شنونده درک شوند.
مورد دیگر این است که تقریباً همه آنها رابطه ساده بین کانال ها و اسپیکرها را شکسته اند. فرمت تحویل صرفاً شامل یک کانال مونو جداگانه برای هر اسپیکر نیست، بلکه یک جریان داده پیچیدهتر است که در زمان واقعی رمزگشایی میشود تا آن را بر روی هر اسپیکری موجود در هر مکان در دسترس قرار دهد.
برخلاف صداهای فراگیر قدیمیتر، بنابراین صدای فراگیر به یک دستگاه «هوشمند» در زنجیره پخش برای انجام این رمزگشایی و نقشهبرداری سفارشی نیاز دارد.
اما در بسیاری از زمینهها، این واقعاً مشکلی نیست، زیرا جریان از رایانه، سرور یا دستگاه دیگری که قدرت پردازش زیادی دارد پخش میشود.
مطمئناً، نیاز احتمالی به یک دستگاه اضافی در زنجیره سیگنال به شدت از مزایای آن غلبه می کند. نکته اصلی این است که در اصل، صدای فراگیر را می توان برای هر چیدمان اسپیکری که دوست دارید رمزگشایی کنید، از اسپیکر مونو با پهنای باند محدود در گوشی هوشمند گرفته تا یک آرایه کامل سینما با تعداد زیادی اسپیکرهای پشتی و جانبی، اسپیکرهای بالای سر و ساب ووفرها.
همچنین می توان آن را از طریق یک رمزگذار دوگوشی تغذیه کرد تا حس غوطه وری در هدفون را به دست آورد. به عبارت دیگر، در حالی که فرمتهای فراگیر قبلی، شنوندگان را ملزم میکردند تا تنظیمات خود را مطابق با فرمت تطبیق دهند، صدای فراگیر خود را با هر تنظیمات موجود سازگار میکند.
ما میتوانیم فرمتهای صوتی فراگیر را بهعنوان کانالمحور، مبتنی بر صحنه یا مبتنی بر شی طبقهبندی کنیم. دسته اول به صداهای فراگیر فراتر از 5.1 اشاره دارد که بلندگوهای بالای شنونده را در خود جای میدهند و بنابراین میتوانند ادعا کنند که غوطهور هستند و در عین حال نگاشت مستقیم و انحصاری کانال به اسپیکر را حفظ میکنند.
در مقابل، فرمتهای مبتنی بر صحنه، یک جریان داده پیچیده و منفرد را ارائه میکنند که یک میدان صوتی کامل سهبعدی را توصیف میکند.
در نهایت، فرمتهای مبتنی بر شی، تعدادی جریان صوتی مجزا را همراه با ابرداده بستهبندی میکنند که به رمزگشا میگوید این جریانهای منفرد چگونه باید قرار گیرند.
به بیان ساده، فرمتهای مبتنی بر کانال و صحنه حاوی صدای کاملاً ترکیبی هستند، در حالی که قالبهای مبتنی بر شی حاوی عناصر اصلی یک میکس بهعلاوه ابرداده است که توضیح میدهد چگونه آن میکس باید در یک محیط پخش معین پیادهسازی شود.
در زمان نگارش این مقاله، تعدادی از فرمتهای تولید و توزیع صوتی تجاری وجود دارد که بهعنوان همهجانبه، فضایی یا سهبعدی نامگذاری میشوند و همگی برای تسلط بر بخشهای مختلف بازار رقابت میکنند. همانطور که خواهیم دید، بسیاری از اینها در واقع فرمت های میکسی هستند که عناصر مبتنی بر شی را با عناصر کانال یا صحنه میکس می کنند.
نمونه اصلی فرمت صوتی سه بعدی مبتنی بر صحنه خالص Ambisonics است. Ambisonics که در اواخر دهه 1970 توسط مایکل گرزون و پیتر کریون توسعه داده شد، می تواند به عنوان یک توسعه استریوی Mid-Sides در نظر گرفته شود.
Mid-Sides همچنین به عنوان “جمع و تفاوت” شناخته می شود، و Ambisonics مرتبه اول این مفهوم را با افزودن دو کانال “تفاوت” اضافی، که محورهای جلو-پشت و بالا-پایین را نشان می دهد، گسترش می دهد.
کانال مجموع یا W جزء همه جهته را توصیف می کند، در حالی که کانال های X، Y و Z بعدی اجزای جهت صدا را در سه صفحه متعامد توصیف می کنند.
Ambisonics را می توان به تعداد نامحدودی از سفارشات مقیاس کرد. تعداد کانال های مورد نیاز برای اجرای یک مرتبه n (n+1) مجذور است، بنابراین Ambisonics مرتبه دوم به 9 کانال، مرتبه سوم 16 و غیره نیاز دارد.
مزیت سفارشهای بالاتر این است که شنونده میتواند منابع را با دقت بیشتری در میدان صوتی بومیسازی کند. به عنوان مثال، دو منبع صوتی مختلف را در نظر بگیرید که از یک نقطه شروع می شوند و به آرامی از هم دور می شوند. هر چه ترتیب بالاتر باشد، زاویه باریک تری می توانیم بین آنها تمایز قائل شویم.
هیچ سیستم پخش در دنیای واقعی وجود ندارد که بتواند سیگنال خام Ambisonics را پخش کند. بنابراین، همانطور که استریو Mid-Sides برای پخش در اسپیکرها یا هدفونهای معمولی باید در کانالهای چپ و راست ماتریس شود، سیگنال Ambisonics نیز باید پردازش شود تا آن را با هر سیستم پخشی که در دسترس است تطبیق دهد.
این می تواند شامل استخراج سیگنال های تک جداگانه برای هر اسپیکر در یک صدای فراگیر یا اجرای سیگنال از طریق یک رمزگذار دوگوشی برای گوش دادن به هدفون باشد.
بنابراین Ambisonics شبیه استریو و فراگیر 5.1 است به این معنا که هر کانال رمزگشایی شده بخشی از یک میدان صوتی کامل را توصیف می کند، نه یک عنصر مجزا در آن میدان صوتی.
تفاوت آن با آن فرمت ها این است که رابطه یک به یک بین کانال ها و بلندگوها از بین رفته است. سیگنال Ambisonic یک نمایش انتزاعی از میدان صوتی است که باید در یک محیط شنیداری خاص ماتریس شود.
در مقابل، در یک قالب مبتنی بر شی، هر کانال یک عنصر خاص از ترکیب را توصیف می کند: یک آواز، یک ساز یا گروهی از سازها، یک افکت فولی مانند یک انفجار یا هر چیز دیگری.
هر شی با مجموعهای از ابردادههای رمزگذاریشده زمانی خود بستهبندی میشود که از دادههای اتوماسیون ترکیب شده و اغلب یکسان است. به عنوان مثال، ابرداده یک آهنگ کوبه ای ممکن است به آن بگوید که تا 30 در فاصله سمت چپ بالای میدان صوتی باقی بماند…
